owllook -- 一个简洁的网络小说搜索引擎
前言
上一篇介绍了自己在使用sanic过程中遇到的一些问题,这次就想介绍下这个owllook,上面是演示demo,具体可以见https://www.owllook.net/
本项目纯属共享学习之用,不得用于商业!
首先我想说下目前的项目进度:
v0.1.0:
- 小说的基本搜索解析功能
- 搜索记录
- 缓存
- 书架
- 书签
- 登录
- 初步兼容手机(后续跟进)
TODO:
- 注册(开放注册)
- 上次阅读
- 最新章节
- 书友推荐(很基础的推荐)
- 目录获取
- 翻页
- 搜索排行
- 部分页面重写(进行中)
- 章节异步加载 感谢@mscststs
- 排行榜
- 阅读书单
- 推荐
交流群:591460519,欢迎提issue
最近将页面重构,见md版本页面
介绍
owllook的思路很简单,利用百度检索出来的结果,进行过滤解析后再展示,使用的技术如下:
- sanic:基于Python 3.5+的异步web服务器,快快快
- sanic_session:sanic的持续会话插件
- vloop:sanic默认使用uvloop,替代asyncio本身的loop
- motor:异步的mongodb驱动
- aiohttp:异步请求
- aiocache:异步缓存,本项目改用了其中的decorator部分,缓存数据库使用redis
owllook使用了mongodb储存了用户使用过程中的产生的基本信息,诸如注册信息、搜索小说信息、收藏小说数据等,对于某些必要的缓存,则利用redis进行缓存处理,如小说缓存、session缓存,注意,对于限制数据:都将在24小时删除。
对于不同网站的小说,页面规则都不尽相同,我希望能够在代码解析后再统一展示出来,这样方便且美观,而不是仅仅跳转到对应网站就完事,清新简洁的阅读体验才是最重要的。
目前采用的是直接在搜索引擎上进行结果检索,具体见规则定义,遇到自己喜欢的小说网站,方便诸位添加解析,owllook目前解析了超过 200+ 网站,追更网站解析了50+。
有一些地方需要用到爬虫,比如说排行榜,一些书籍信息等,我不想动用重量级爬虫框架来写,于是我在owllook里面编写了一个很轻量的爬虫框架来做这件事,见talospider。
BTW,sanic写界面确实不是很方便,至于为什么写这个,一是想利用sanic尽量做成异步服务,二是想就此练习下推荐系统,顺便作为毕业设计。
一般都是在下班时间编写这个项目,目前v0.1版本大概实现。
解析
这个项目的思路与技术都比较简单,但是小说网站的解析工作是很难全部解析完毕,下面我将举个例子怎么具体的解析一个网站,欢迎各位添砖加瓦,请先看一遍规则定义。 解析也很简单,只要求有点html以及css基础即可。
首先进入网站http://www.owllook.net/。
搜索:
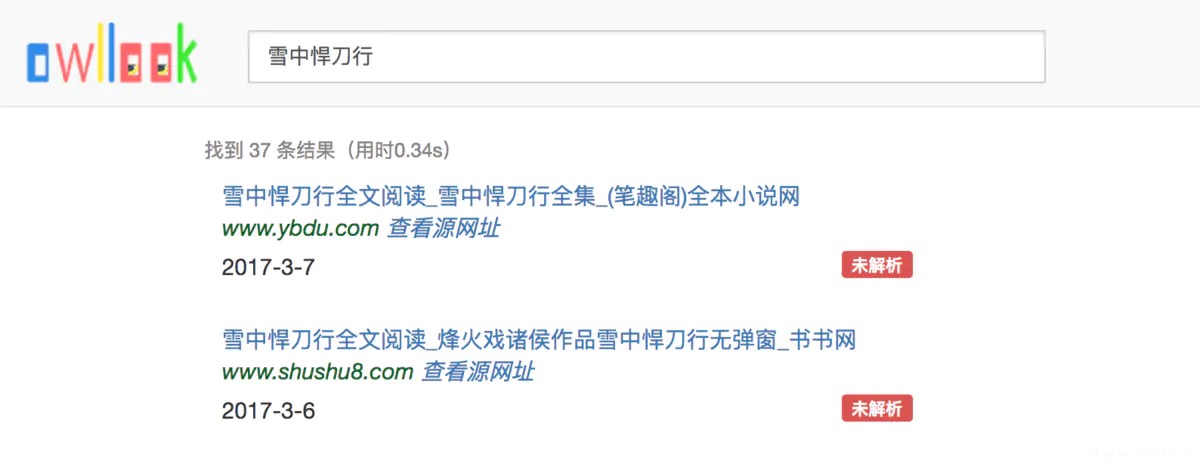
注意第一条结果显示未解析,这就是我们要解析的对象了,点击进入源网站,审查小说目录对应的元素,这里显示的是:class="mulu_list,然后注意其content_url类型是0
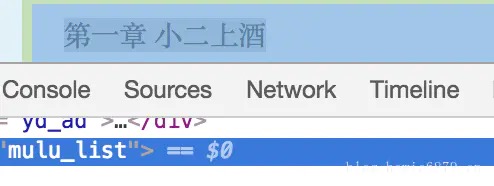
进入小说章节内容页面,审查元素可以看到id=htmlContent,所以content_selector=htmlContent
接下来进入项目,打开config/rules.py文件,在RULES字典中加入:
|
|
这时候再重启服务,刷新页面:
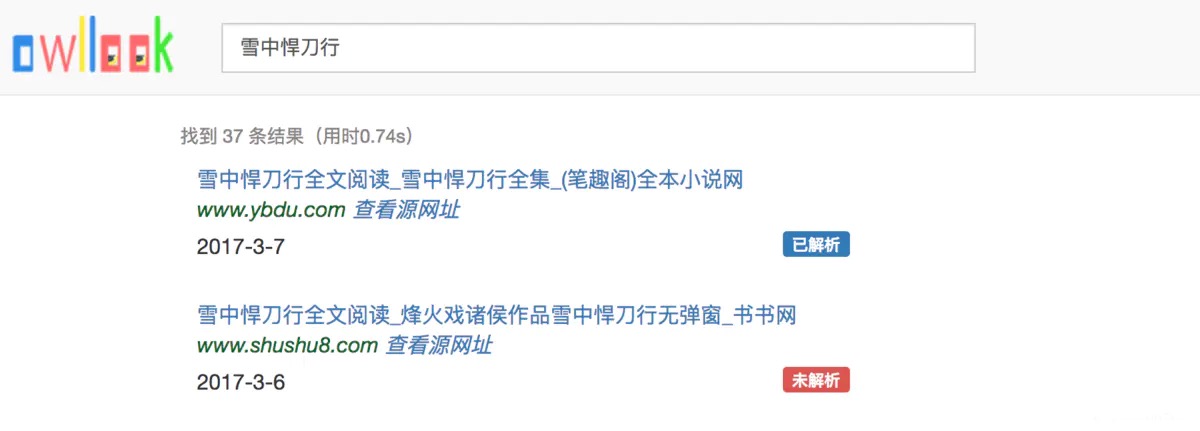
可以看到未解析变成了已解析,这时候点击进入,会出现两种情况:
- 排版完整,不需要再写样式,此时请直接解析章节内容
- 排版不行,需要写样
现在我演示的这个链接排版就是显示不行,请打开/static/novels/css/chapter.css文件,在编写之前,请先看下面这张图:
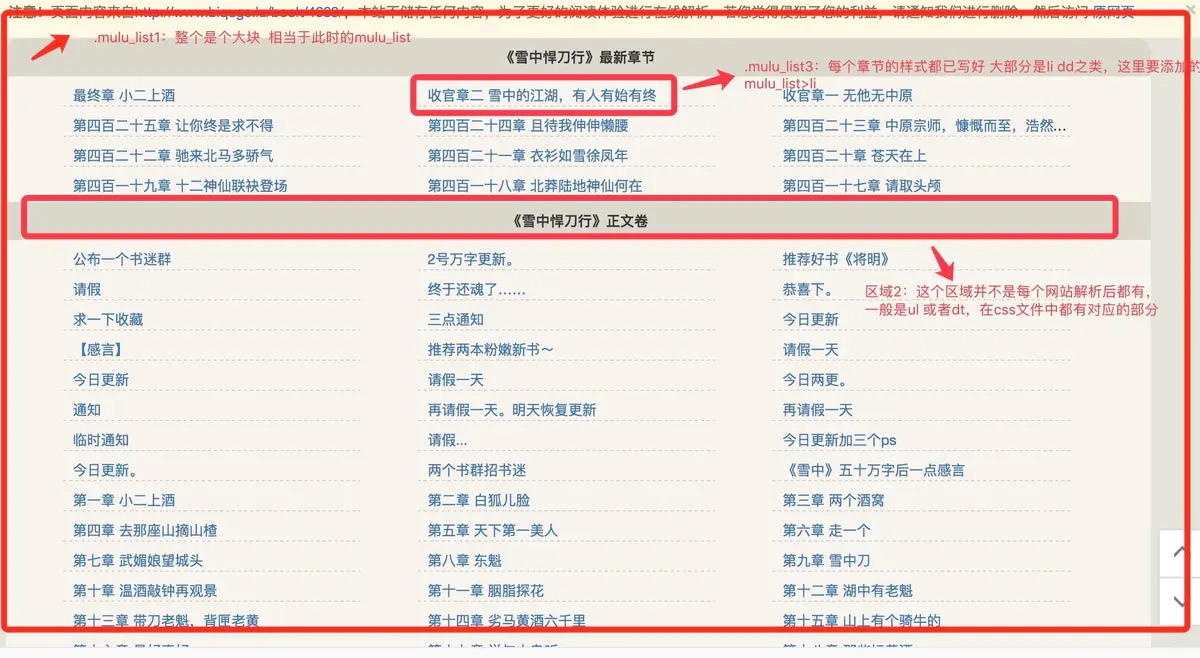
图中.mulu_list1:打错了表示区域1,.mulu_list1:表示区域3.
首先更改区域1的样式,我已经在代码注释写了各个区域样式代码在哪,直接更改就行,比如:
|
|
可以看到加上了.mulu_list,以此类推,最后解析完毕之后如下图:

注意章节内容里面一些无关的链接以及原本网页自带的上一章下一章需要隐藏掉哦。
总结
功能还很简单,解析的网站有很多,希望各位添砖加瓦,容我奉上项目地址:owllook
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2017/07_owllook-intro/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
