这是我参加mlhub123组织的书籍共读计划的读书笔记,活动见mlhub第一期读书计划
- 阅读章节:第二章:感知机
- 开始时间:2018-09-18
- 结束时间:2018-09-21
- 目标:读完第二章,掌握基本概念,产出一篇笔记
- 博客地址
本章主要介绍了二类分类的线性分类模型:感知机:
说明:个人感觉这本书偏理论化,讲究的是一招定天下,好处是内功深厚自然无敌,一通百通,但难处是语言有点晦涩,这章可以考虑结合我之前的一篇关于感知器的笔记,或许能加深理解,见这里
感知机模型
感知机(perceptron):是一个二类分类的线性判断模型,其输入为实例的特征向量,输出为实例的类别,取+1和–1值,属于判别模型
注:+1 -1 分别代表正负类,有的可能用 1 0 表示
在介绍感知机定义之前,下面几个概念需要说明一下:
- 输入空间:输入所有可能取值的集合
- 输出空间:输出所有可能取值的集合
- 特征空间:每个具体的输入是一个实例,由特征向量表示
所以对于一个感知机模型,可以这样表示:
- 输入空间(特征空间):$\chi \subseteq \mathbb{R} ^n$
- 输出空间:$\gamma = \{+1,-1 \}$
那么感知机就是由输入空间到输出空间的函数:
$$\displaystyle f( x) \ =\ sign( w\cdot x+b)$$
其中:
- $sign$: 符号函数
- $w$: 权值(weight)或权值向量(weight vector)
- $b$: 偏置(bias)
感知机的几何解释如下:线性方程
$$w\cdot x + b =0$$
如果是二维空间,感知机就是一个线性函数,将正负样本一分为二,如何是三维空间,那么感知机就是一个平面将类别一切为二,上升到n维空间的话,其对应的是特征空间$\mathbb{R} ^n$的一个超平面$S$:
感知机学习策略
数据集的线性可分性
什么是数据集的线性可分性,很简单,对于一个数据集:
$$T = {(x_1,y_1),(x_2,y_2),…,(x_n,y_n)}$$
如果存在上面一节说的超平面$S$:$w\cdot x + b =0$,能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,则称数据集T为线性可分数据集(linearly separable data set),否则,称数据集T线性不可分
感知机学习策略
找出超平面$S$,其实就是确定感知机模型参数:$w b$,根据统计学习方法三要素,此时我们需要确定一个学习策略,比如前面所说的损失函数(经验函数),并使其最小化(猜也猜得到策略讲完,后面就是说学习算法了哈哈)
上一章以线性代数为例子,用损失函数来度量预测错误的程度,这里的损失函数可以用误分类点到超平面$S$的总距离,输入空间$\mathbb{R} ^n$中任一点$x_0$到超平面$S$的距离:
$$\frac{1}{||w||}|w\cdot x_0+b|$$
其中,$||w||$是$w$的$L_2$范数,假设超平面S的误分类点集合为$M$,那么所有误分类点到超平面$S$的总距离为:
$$-\frac{1}{||w||}\sum_{x_i\in M} y_i(w\cdot x_i + b)$$
最终推导出感知机学习的损失函数:
$$L(w,b) =-\sum_{x_i\in M} y_i(w\cdot x_i + b)$$
感知机学习算法
上面一节已经确定了学习策略,按照统计学习方法三要素,目前需要一个算法来求解,目前最优化的方法是随机梯度下降法
感知机学习算法的原始形式
现在感知机学习算法就是对下面最优化问题的算法:
$$ \min_{w,b} L(w,b) =-\sum_{x_i\in M} y_i(w\cdot x_i + b) $$
现在的问题就转化成,求出参数$w$和$b$,使得上列损失函数达到极小化,这里我直接贴出书中的算法,后面的例子我会用Python代码实现:

有了解题方法怎么能没有题目呢?李杭老师自然是考虑到了,请听题:

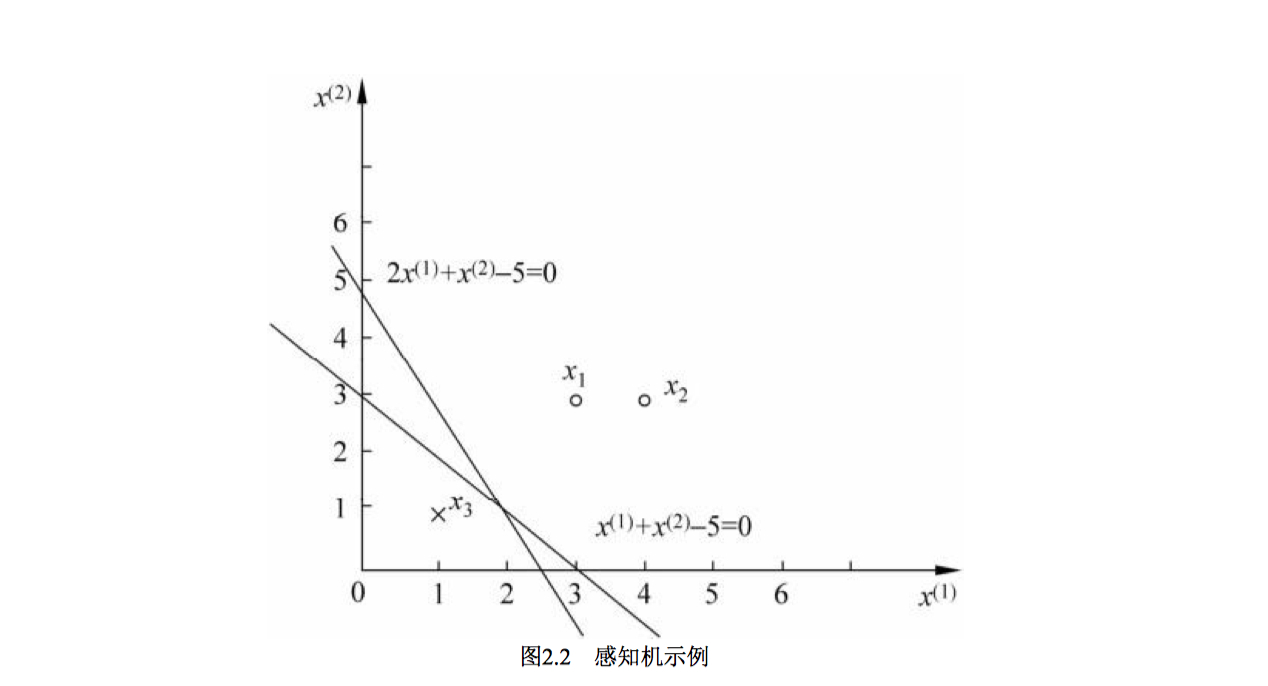
借用Linus Torvalds大佬的一句话:Talk less, show me your code,所以直接看代码吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#!/usr/bin/env python
"""
Created by howie.hu at 2018/9/20.
"""
import numpy as np
class Perceptron:
"""
李航老师统计学习方法第二章感知机例2.1代码实现
"""
def __init__(self, input_nums=2):
# 权重 已经确定只会有两个二进制输入
self.w = np.zeros(input_nums)
# 偏置项
self.b = 0.0
def fit(self, input_vectors, labels, learn_nums=10, rate=1):
"""
训练出合适的 w 和 b
:param input_vectors: 样本训练数据集
:param labels: 标记值
:param learn_nums: 学习多少次
:param rate: 学习率
"""
for i in range(learn_nums):
for index, input_vector in enumerate(input_vectors):
label = labels[index]
delta = label * (sum(self.w * input_vector) + self.b)
if delta <= 0:
# 计算方法由梯度下降算法推导出来
self.w += label * input_vector * rate
self.b += rate * label
break
print("最终结果:此时感知器权重为{0},偏置项为{1}".format(self.w, self.b))
return self
def predict(self, input_vector):
"""
跃迁函数作为激活函数,感知器
:param input_vector:
:return:
"""
if isinstance(input_vector, list):
input_vector = np.array(input_vector)
y = sum(self.w * input_vector) + self.b
return 1 if y > 0 else -1
if __name__ == '__main__':
input_vectors = np.array([[3, 3], [4, 3], [1, 1]])
labels = np.array([1, 1, -1])
p = Perceptron()
model = p.fit(input_vectors, labels)
print(model.predict([3, 3]))
print(model.predict([4, 3]))
print(model.predict([1, 1]))
|
输出如下:
1
2
3
4
|
最终结果:此时感知器权重为[ 1. 1.],偏置项为-3.0
1
1
-1
|
代码写完了,再看看推导过程:

算法的收敛性
对于线性可分数据集感知机学习算法原始形式收敛,即经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平面及感知机模型,定理2.1如下:
假设训练数据集$T = {(x_1,y_1),(x_2,y_2),…,(x_n,y_n)}$是线性可分的,其中$x_i\in \chi =\mathbb{R} ^n$,$y_i \in \gamma =\{-1, 1\}$,$i=1,2,…,N$,则有:

感知机学习算法的对偶形式
为什么要介绍感知机学习算法的对偶形式,主要目的就是减少运算量,这里一个知乎回答得挺好:


代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
#!/usr/bin/env python
"""
Created by howie.hu at 2018/9/21.
"""
import numpy as np
class Perceptron:
"""
李航老师统计学习方法第二章感知机例2.2对偶形式代码实现
"""
def __init__(self, alpha_length=3):
self.alpha = np.zeros(alpha_length)
# 权重
self.w = np.zeros(2)
# 偏置项
self.b = 0.0
def fit(self, input_vectors, labels, learn_nums=7):
"""
训练出合适的 w 和 b
:param input_vectors: 样本训练数据集
:param labels: 标记值
:param learn_nums: 学习多少次
"""
gram = np.matmul(input_vectors, input_vectors.T)
for i in range(learn_nums):
for input_vector_index, input_vector in enumerate(input_vectors):
label = labels[input_vector_index]
delta = 0.0
for alpha_index, a in enumerate(self.alpha):
delta += a * labels[alpha_index] * gram[input_vector_index][alpha_index]
delta = label * delta + self.b
if delta <= 0:
self.alpha[input_vector_index] += 1
self.b += label
break
self.w = sum([j * input_vectors[i] * labels[i] for i, j in enumerate(self.alpha)])
print("最终结果:此时感知器权重为{0},偏置项为{1}".format(self.w, self.b))
return self
def predict(self, input_vector):
if isinstance(input_vector, list):
input_vector = np.array(input_vector)
y = sum(self.w * input_vector) + self.b
return 1 if y > 0 else -1
if __name__ == '__main__':
input_vectors = np.array([[3, 3], [4, 3], [1, 1]])
labels = np.array([1, 1, -1])
p = Perceptron()
model = p.fit(input_vectors, labels)
print(model.predict([3, 3]))
print(model.predict([4, 3]))
print(model.predict([1, 1]))
|
1
2
3
4
|
最终结果:此时感知器权重为[ 1. 1.],偏置项为-3.0
1
1
-1
|
说明
一些概念的详细解释:
