谈谈对Python爬虫的理解
谈谈对Python爬虫的理解
爬虫也可以称为Python爬虫
不知从何时起,Python这门语言和爬虫就像一对恋人,二者如胶似漆 ,形影不离,你中有我、我中有你,一提起爬虫,就会想到Python,一说起Python,就会想到人工智能……和爬虫
所以,一般说爬虫的时候,大部分程序员潜意识里都会联想为Python爬虫,为什么会这样,我觉得有两个原因:
- Python生态极其丰富,诸如Request、Beautiful Soup、Scrapy、PySpider等第三方库实在强大
- Python语法简洁易上手,分分钟就能写出一个爬虫(有人吐槽Python慢,但是爬虫的瓶颈和语言关系不大)
任何一个学习Python的程序员,应该都或多或少地见过甚至研究过爬虫,我当时写Python的目的就非常纯粹——为了写爬虫。所以本文的目的很简单,就是说说我个人对Python爬虫的理解与实践,作为一名程序员,我觉得了解一下爬虫的相关知识对你只有好处,所以读完这篇文章后,如果能对你有帮助,那便再好不过
什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取
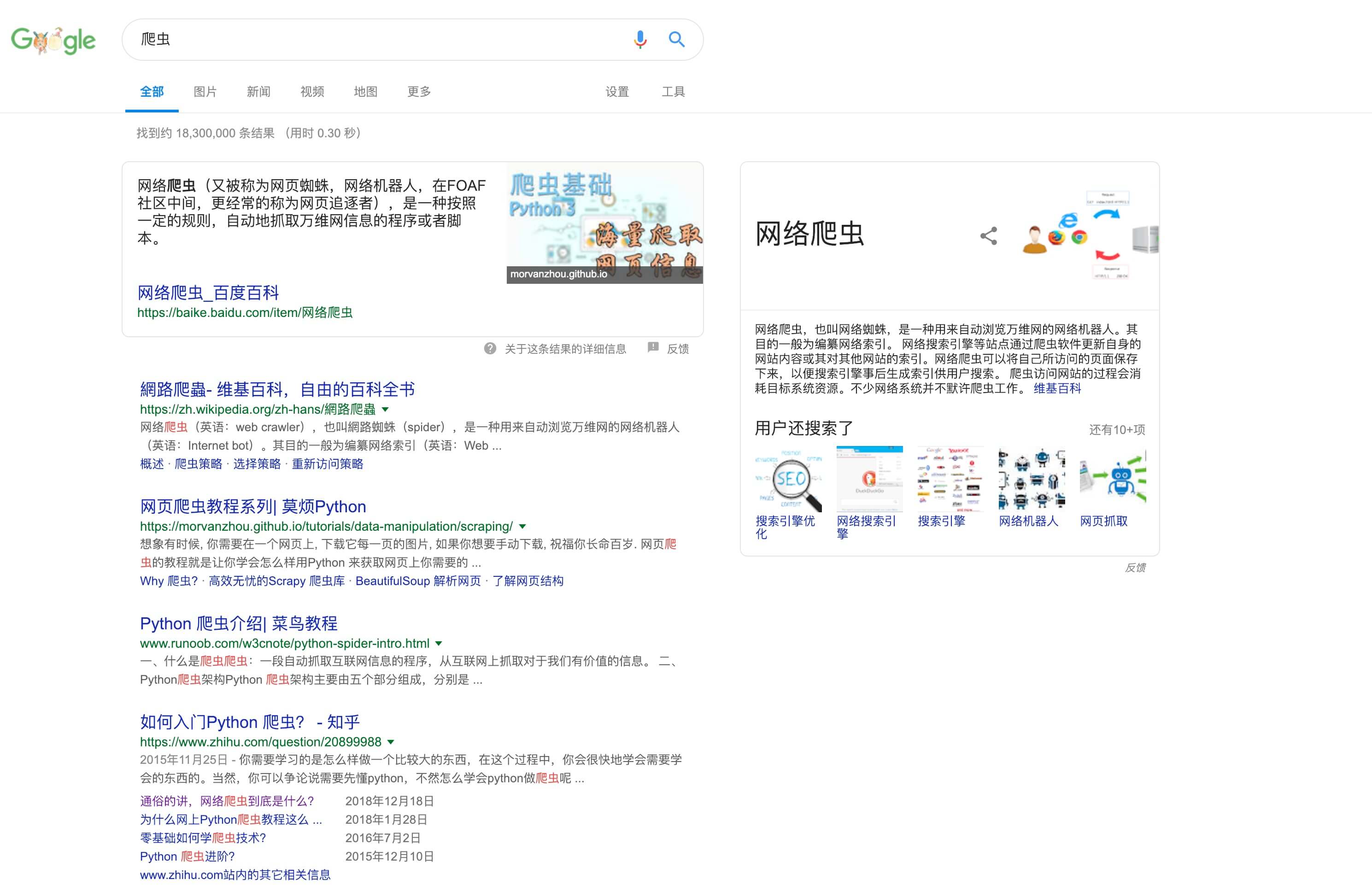
看上述搜索结果,除了wiki相关介绍外,爬虫有关的搜索结果全都带上了Python,前人说Python爬虫,现在看来果然诚不欺我~
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何结构化非结构化的数据爬虫都可以爬取,爬虫经过发展,也衍生出了各种爬虫类型:
- 通用网络爬虫:爬取对象从一些种子 URL 扩充到整个 Web,搜索引擎干的就是这些事
- 垂直网络爬虫:针对特定领域主题进行爬取,比如专门爬取小说目录以及章节的垂直爬虫
- 增量网络爬虫:对已经抓取的网页进行实时更新
- 深层网络爬虫:爬取一些需要用户提交关键词才能获得的 Web 页面
不想说这些大方向的概念,让我们以一个获取网页内容为例,从爬虫技术本身出发,来说说网页爬虫,步骤如下:
- 模拟请求网页资源
- 从HTML提取目标元素
- 数据持久化
什么是爬虫,这就是爬虫:
|
|
加上注释不到20行代码,你就完成了一个爬虫,简单吧
怎么写爬虫
网页世界多姿多彩、亿万网页资源供你选择,面对不同的页面,怎么使自己编写的爬虫程序够稳健、持久,这是一个值得讨论的问题
俗话说,磨刀不误砍柴工,在开始编写爬虫之前,很有必要掌握一些基本知识:
- 网页的结构是HTML,爬虫的目标就是解析HTML,获取目标字段并保存
- 客户端展现的网页由浏览器渲染,客户端和服务端的信息交互依靠HTTP协议
这两句描述体现了一名爬虫开发人员需要掌握的基本知识,不过一名基本的后端或者前端工程师都会这些哈哈,这也说明了爬虫的入门难度极低,从这两句话,你能思考出哪些爬虫必备的知识点呢?
- 基本的HTML知识,了解HTML才方便目标信息提取
- 基本的JS知识 ,JS可以异步加载HTML
- 了解CSS Selector、XPath以及正则,目的是为了提取数据
- 了解HTTP协议,为后面的反爬虫斗争打下基础
- 了解基本的数据库操作,为了数据持久化
有了这些知识储备,接下来就可以选择一门语言,开始编写自己的爬虫程序了,还是按照上一节说的三个步骤,然后以Python为例,说一说要在编程语言方面做那些准备:
- 网页请求:内置有urllib库,第三方库的话,同步请求可以使用requests,异步请求使用aiohttp
- 分析HTML结构并提取目标元素:CSS Selector和XPath是目前主流的提取方式,第三方库可以使用Beautiful Soup或者PyQuery
- 数据持久化:目标数据提取之后,可以将数据保存到数据库中进行持久化,MySQL、MongoDB等,这些都有对应的库支持,当然你也可以保存在硬盘,谁硬盘没点东西对吧(滑稽脸)
掌握了上面这些,你大可放开手脚大干一场,万维网就是你的名利场,去吧~
我觉得对于一个目标网站的网页,可以分下面四个类型:
- 单页面单目标
- 单页面多目标
- 多页面单目标
- 多页面多目标
具体是什么意思呢,可能看起来有点绕,但明白这些,你之后写爬虫,只要在脑子里面过一遍着网页对应什么类型,然后套上对应类型的程序(写多了都应该有一套自己的常用代码库),那写爬虫的速度,自然不会慢
单页面单目标
通俗来说,就是在这个网页里面,我们的目标就只有一个,假设我们的需求是抓取这部 电影-肖申克的救赎 的名称,首先打开网页右键审查元素,找到电影名称对应的元素位置,如下图所示:
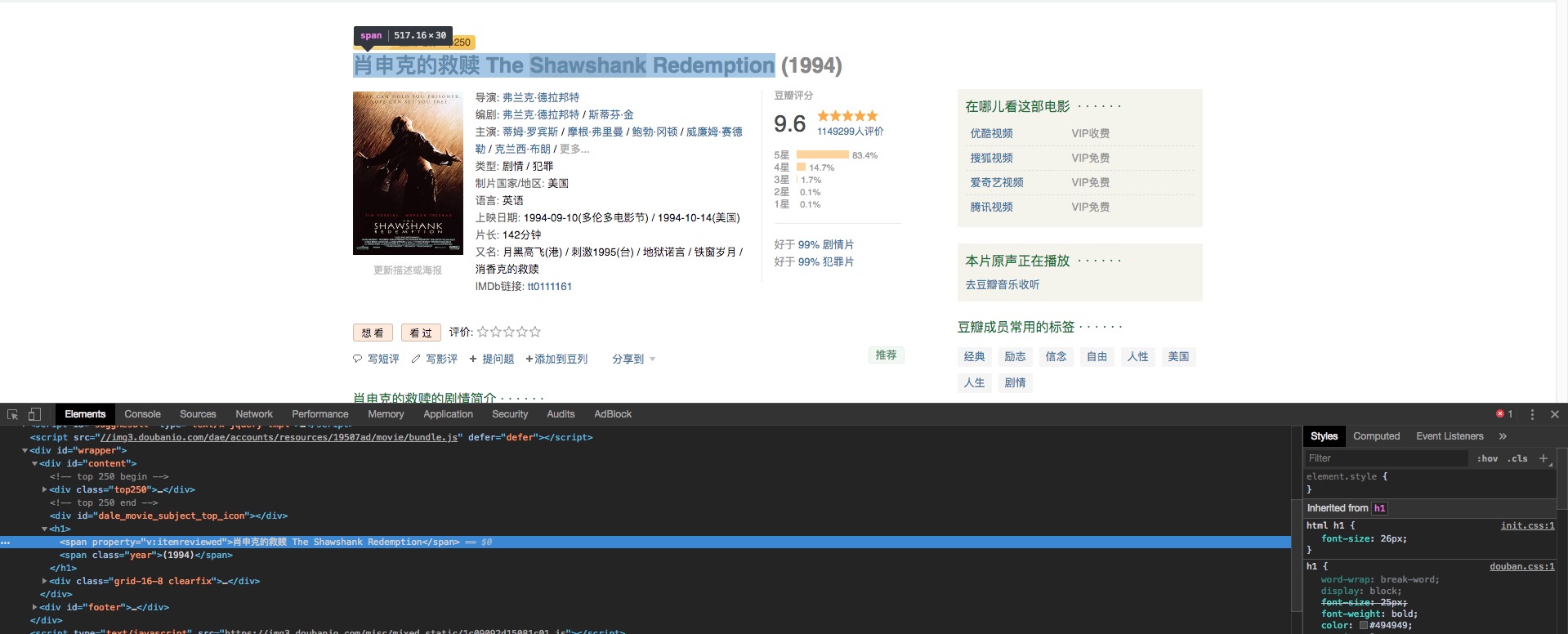
在某个单一页面内,看目标是不是只有一个,一眼就能看出标题的CSS Selector规则为:#content > h1 > span:nth-child(1),然后用我自己写的常用库,我用不到十行代码就能写完抓取这个页面电影名称的爬虫:
|
|
多页面多目标就是此情况下多个url的衍生情况
单页面多目标
假设现在的需求是抓取 豆瓣电影250 第一页中的所有电影名称,你需要提取25个电影名称,因为这个目标页的目标数据是多个item的,所以目标需要循环获取。
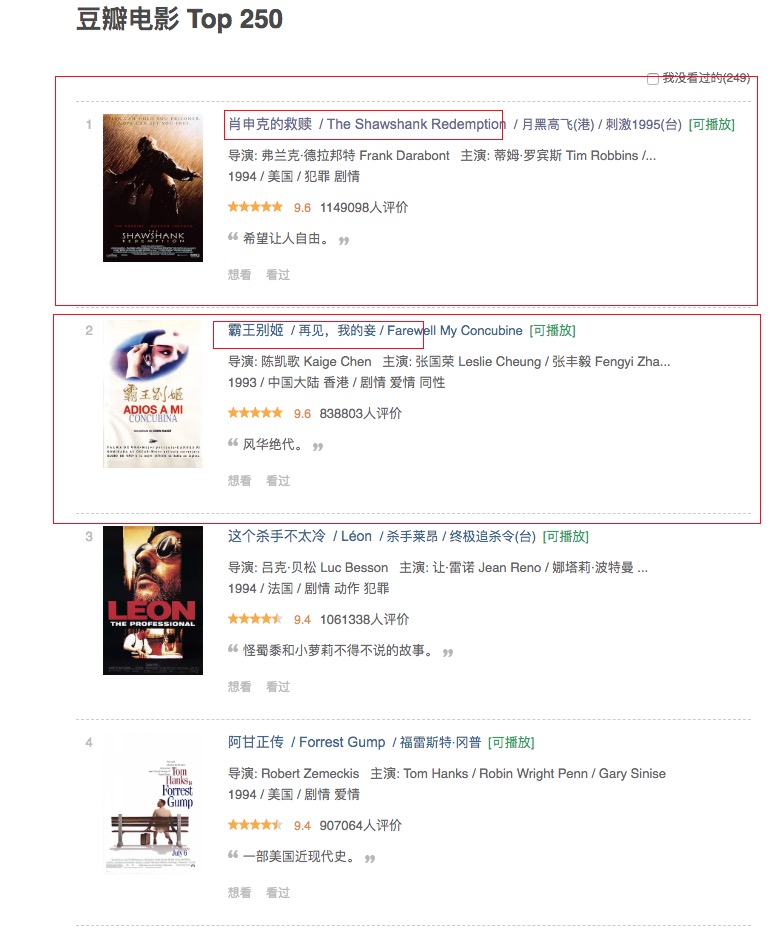
对于这个情况,我在Item中限制了一点,当你定义的爬虫需要在某一页面循环获取你的目标时,则需要定义target_item属性(就是截图中的红框)
对于豆瓣250这个页面,我们的目标是25部电影信息,所以该这样定义:
| field | css_select |
|---|---|
| target_item(必须) | div.item |
| title | span.title |
代码实现如下:
|
|
多页面多目标
多页面多目标是上述单页面多目标情况的衍生,在这个问题上来看,此时就是获取所有分页的电影名称
|
|
如果网络没问题的话,会得到如下输出:
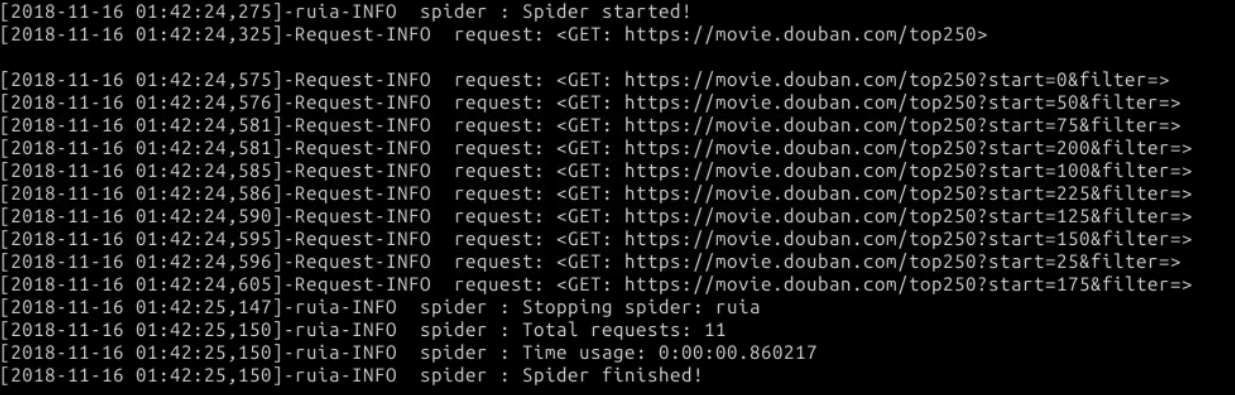
注意爬虫运行时间,1s不到,这就是异步的魅力
用Python写爬虫,就是这么简单优雅,诸位,看着网页就思考下:
- 是什么类型的目标类型
- 用什么库模拟请求
- 怎么解析目标字段
- 怎么存储
一个爬虫程序就成型了,顺便一提,爬虫这东西,可以说是防君子不防小人,robots.txt大部分网站都有(它的目的是告诉爬虫什么可以爬取什么不可以爬取,比如:https://www.baidu.com/robots.txt),各位想怎么爬取,自己衡量
如何进阶
不要以为写好一个爬虫程序就可以出师了,此时还有更多的问题在前面等着你,你要含情脉脉地看着你的爬虫程序,问自己三个问题:
- 爬虫抓取数据后是正当用途么?
- 爬虫会把目标网站干掉么?
- 爬虫会被反爬虫干掉么?
前两个关于人性的问题在此不做过多叙述,因此跳过,但你们如果作为爬虫工程师的话,切不可跳过
会被反爬虫干掉么?
最后关于反爬虫的问题才是你爬虫程序强壮与否的关键因素,什么是反爬虫?
当越来越多的爬虫在互联网上横冲直撞后,网页资源维护者为了防止自身数据被抓取,开始进行一系列的措施来使得自身数据不易被别的程序爬取,这些措施就是反爬虫
比如检测IP访问频率、资源访问速度、链接是否带有关键参数、验证码检测机器人、ajax混淆、js加密等等
对于目前市场上的反爬虫,爬虫工程师常有的反反爬虫方案是下面这样的:
- 不断试探目标底线,试出单IP下最优的访问频率
- 构建自己的IP代理池
- 维护一份自己常用的UA库
- 针对目标网页的Cookie池
- 需要JS渲染的网页使用无头浏览器进行代码渲染再抓取
- 一套破解验证码程序
- 扎实的JS知识来破解混淆函数
爬虫工程师的进阶之路其实就是不断反反爬虫,可谓艰辛,但换个角度想也是乐趣所在
关于框架
爬虫有自己的编写流程和标准,有了标准,自然就有了框架,像Python这种生态强大的语言,框架自然是多不胜数,目前世面上用的比较多的有:
- Scrapy
- PySpider
- Portia
- Ruia:容我自荐一波
这里不过多介绍,框架只是工具,是一种提升效率的方式,看你选择
说明
任何事物都有两面性,爬虫自然也不例外,因此我送诸位一张图,关键时刻好好想想
最后,欢迎一起交流:
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2019/02_talk_about_python_spider/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
