nndl_note: 识别手写字

Neural Networks and Deep Learning 是由 Michael Nielsen 编写的开源书籍,这本书主要讲的是如何掌握神经网络的核心概念,包括现代技术的深度学习,为你将来使⽤神经网络和深度学习打下基础,以下是我的读书笔记。
神经网络是一门重要的机器学习技术,它通过模拟人脑的神经网络来实现人工智能的目的,所以其也是深度学习的基础,了解它之后自然会受益颇多,本章主要是以识别手写字这个问题来贯穿整篇,那么,人类的视觉系统和神经网络到底在识别一个目标的时候,主要区别在哪?
- 人类视觉系统:通过数十亿年不断地进化与学习,最终能够极好地适应理解视觉世界的任务,从而无意识地就可以对目标进行判断识别
- 神经网络:通过提供的样本来推断出识别某种目标的规则,作为判断标准
本章的主要内容是介绍神经网络的基本概念以及引入一个识别手写数字的例子来加深我们的理解,你将了解到:
- 两个重要的人工神经元:感知器和S型神经元
- 神经⽹络的架构
- ⼀个简单的分类⼿写数字的⽹络
- 标准的神经网络学习算法:随机梯度下降算法
感知器
1943年,心理学家McCulloch和数学家Pitts发表了《A logical calculus of the ideas immanent in nervous activity》,其中提出了抽象的神经元模型MP,但是在这个模型中权重都是要求提前设置好才可以输出目标值,所以很遗憾,它不可以学习,但这不影响此模型给后来者带来的影响,比如感知器:
感知器是Frank Rosenblatt提出的一个由两层神经元组成的人工神经网络,它的出现在当时可是引起了轰动,因为感知器是首个可以学习的神经网络
感知器的工作方式如下所示:
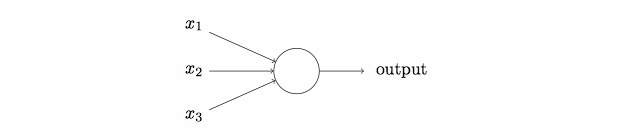
$x_{1},x_{2},x_{3}$ 分别表示三个不同的二进制输入,output则是一个二进制输出,对于多种输入,可能有的输入成立有的不成立,在这么多输入的影响下,该如何判断输出output呢?Rosenblatt引入了权重来表示相应输入的重要性。
对于$x_{1},x_{2},…,x_{j}$个输入,每个输入都有对应的权重$w_{1},w_{2},…,w_{j}$,最后的输出output由每个输入与其对应的权重相乘之和与阈值之差$\sum _{j} w{_j}x{_j}$来决定,如下:

假设$b=-threshold$且$w$和$x$对应权重和输⼊的向量,即:
- $x=(x_{1},x_{2},…,x_{j})$
- $w=(w_{1},w_{2},…,w_{j})$
那么感知器的规则可以重写为:
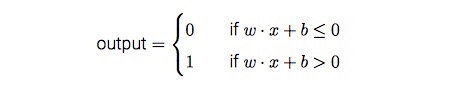
这就是感知器的数学模型,是不是就像一个逻辑回归模型?只要将感知器输出规则替换为($f(x)=x$),后面我们会知道这称之为激活函数,其实这种感知器叫做线性单元。
它的出现让我们可以设计学习算法,从而实现自动调整人工神经元的权重和偏置,与此同时output也会随之改变,这就是学习!如果你有兴趣可以看我用python写的一个感知器自动学习实现与非门,代码在nndl_chapter01。
说句题外话,由于感知器是单层神经网络,它只能实现简单的线性分类任务,所以它无法对异或问题进行分类,异或的真值表如下:
| $x$ | $y$ | $output$ |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
可以看出来,异或问题是线性不可分的,不信你画个坐标轴试试看,那么问题来了?怎么解决,大部分都能很快地想出解决方案,既然感知器可以实现线性分类,也就是说实现与非门是没有问题的,逻辑上来说我们可以实现任何逻辑功能(比如四个与非门实现异或),但前提是为感知器加入一个隐藏层,意思就是多了一个隐藏层的神经网络之后,就可以解决异或问题。
可是在当时是没办法对多层神经网络(包括异或逻辑)进行训练的,因为计算量太大了,Minsky在1969年出版了一本叫《Perceptron》的书详细说明了这个问题。
遇到问题,就解决问题,两层神经网络的作用,是可以对非线性进行分类的,我们的先人并未止步,直到反向传播(Backpropagation,BP)算法的出现解决了计算量太大的问题。
感知器,终于可以多层了。
S型神经元
前面提到,神经网络可以通过样本的学习来调整人工神经元的权重和偏置,从而使输出的结果更加准确,那么怎样给⼀个神经⽹络设计这样的算法呢?
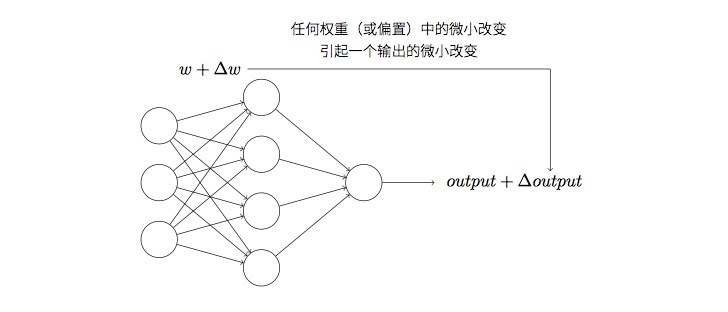
以数字识别为例,假设⽹络错误地把⼀个9的图像分类为8,我们可以让权重和偏置做些⼩的改动,从而达到我们需要的结果9,这就是学习。对于感知器,我们知道,其返还的结果不是0就是1,很可能出现这样一个情况,我们好不容易将一个目标,比如把9的图像分类为8调整回原来正确的分类,可此时的阈值和偏置会造成其他样本的判断失误,这样的调整不是一个好的方案。
所以,我们需要S型神经元,因为S型神经元返回的是[0,1]之间的任何实数,这样的话权重和偏置的微⼩改动只会引起输出的微⼩变化,此时的output可以表示为$\sigma(w \cdot x+b)$,而$\sigma$就是S型函数,S型函数中S指的是Sigmoid函数,定义如下:
$$ \sigma(z) \equiv \frac{1}{1+e^{-z}} $$
其中$z$表达式为:
$$z=\sum_{j} w{_j}x{_j}+b$$
那么⼀个具有输⼊$x_{1},x_{2},…,x_{j}$,权重为$w_{1},w_{2},…,w_{j}$,和偏置b的S型神经元的输出是:
$$ \frac{1}{1+\exp(-\sum_j w_j x_j-b)} $$
上面说过,感知器的激活函数只会输出两个值,分别是0或1,让我们把目光投向S型神经元,假设此时$z$是一个很大的正数,那么此时output将无限接近于1,反之,若$z$是一个很大的负数,那么此时output将无限接近于0,从极端情况来看,是不是很像S型神经元呢?
S型神经元的输出是[0,1]之间的任何实数,那么这个分类模型该如何判断分类结果呢?其实很简单,我们可以定义一个数值,比如:
- $\sigma(z) \leq 0.5$ 输出0
- $\sigma(z)>0.5$ 输出1
神经⽹络的架构
看下面一个四层神经网络,这种类型的多层⽹络有时被称为多层感知器或者MLP,如下图:
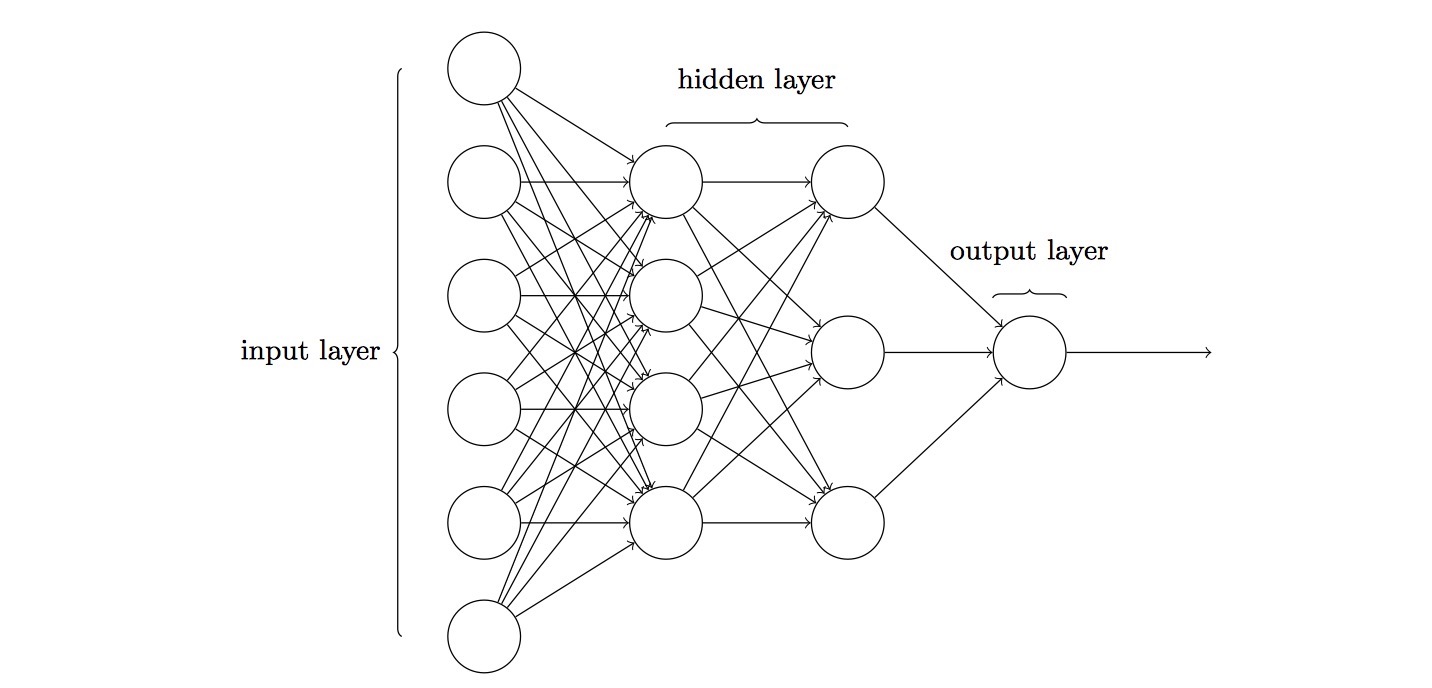
需要记住以下几个概念:
- ⽹络中最左边的称为输⼊层,其中的神经元称为输⼊神经元
- 中间得称之为隐藏层,图中有两个隐藏层
- 最右边称之为输出层
- 上⼀层的输出作为下⼀层的输⼊,信息总是向前传播,从不反向回馈:前馈神经网络
- 有回路,其中反馈环路是可⾏的:递归神经网络
⼀个简单的分类⼿写数字的⽹络
对于这六个数字504192,我们该如何实现一个分类⼿写数字的⽹络呢,可以将其分解为两个小问题:
-
504192是连续在一起的图像,首先可以将其分割成6个小图像,比如
50…等 -
再对分割开的小图像进行分类,比如识别
5我们将使⽤⼀个三层神经⽹络来识别单个数字: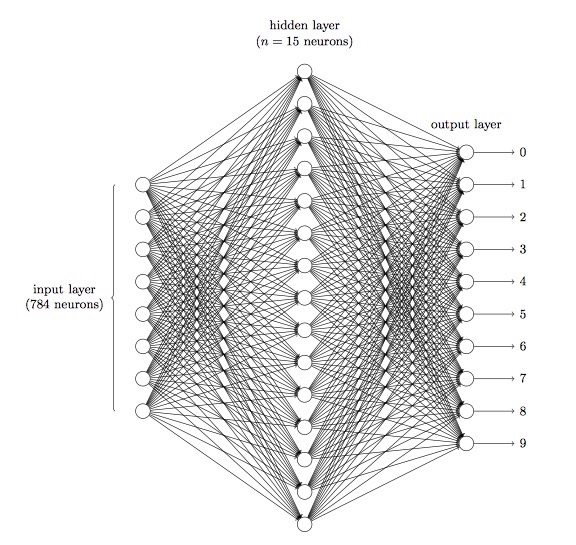 由于训练数据由$28*28$的⼿写数字的图像组成,所以:
由于训练数据由$28*28$的⼿写数字的图像组成,所以: -
输入层有784个神经元,因为$784 = 28 \times 28$,输⼊像素是灰度级的,值为0:0表⽰⽩⾊,值为1:0表⽰⿊⾊,中间数值表⽰逐渐暗淡的灰⾊
-
隐藏层⽤n来表⽰神经元的数量,我们将给n实验不同的数值。⽰例中⽤⼀个⼩的隐藏层来说明,仅仅包含$n = 15$个神经元
-
⽹络的输出层包含有10个神经元,如果第一个输出神经元被激活,那么数字就是0,以此类推,从0到9
一个分类⼿写数字的⽹络,大概就可以这样实现。
随机梯度下降算法
分类方案已经确定了,接下来第一步就是获取样本,我们将使⽤MNIST数据集,其包含有数以万计的连带着正确分类器的⼿写数字的扫描图像,下载好建立这样的目录结构,使用jupyter notebook开始吧,如果没有,请自行检索教程安装,代码目录如下:
|
|
然后使用 TensorFlow来读取数据,看看下载的数据集到底是什么样子,可以在mnist_data.ipynb中添加如下代码:
|
|
查看一些基本信息:
|
|
可以看到显示如下图像:
通过代码,我们知道,每个图像被分割成784个值存于一维数组中,看作⼀个$28 \times 28 = 784$维的向量,每个向量就代表图像中单个像素的灰度值,假设我们用$y$表示output,也就是当我们输入一组样本数据x,那么y就是我们需要的结果,怎么从x得到y呢,我们需要一个函数$y= y(x)$。
感知器为什么可以学习,因为它可以调整$b$和$w$来实现output的改变,这里,我们同样需要一个算法来让我们找到权重和偏置,从而使得$y= y(x)$可以拟合样本输入的x,为了量化我们如何实现这个⽬标,我们定义⼀个代价函数(有时被称为损失或⽬标函数):
$$ C(w,b) \equiv \frac{1}{2n} \sum_x | y(x) - a|^2 $$
- w 表⽰所有的⽹络中权重的集合
- b 是所有的偏置
- n 是训练输⼊数据的个数
- a 是表⽰当输⼊为x时输出的向量,可以理解为output
训练模型的过程就是优化代价函数的过程,Cost Function(代价函数) 越小,就代表模型拟合的越好,所以我们的目的是找出最⼩化权重和偏置的代价函数$C(w,b)$,其实这个就是我们平常用来评价回归算法的均方误差,也就是MSE。
现在我们的目标很清晰,为了找出合适的权重和偏置值,我们需要让代价函数的值接近于0,在这个条件下我们就可以找出合适的权重和偏置值,我们将采⽤称为梯度下降的算法来达到这个⽬的。
下面是我的推导过程:

实现数字分类模型
终于,掌握了基本的概念,我们可以通过实战来实现一个数字分类模型,来看看,前面我们掌握的知识是怎么运用于实际的。
书籍作者很贴心地实现了模型代码,仓库见neural-networks-and-deep-learning 官方git仓库,接下来我们一起来看看具体的实现代码吧。
首先是实现一个Network类,
|
|
前面已经说了S型神经元,那么此时激活函数实现如下,更加具体的代码请参考network.py:
|
|
代码已经准备就绪,下面可以开始进行模型训练:
|
|
看结果,十次迭代后,轻轻松松突破94%
参考
- 文中涉及代码
- Neural Networks and Deep Learning
- Neural Networks and Deep Learning 中文版
- 神经网络浅讲:从神经元到深度学习
- neural-networks-and-deep-learning 官方git仓库
搞定收工,有兴趣欢迎关注我的公众号:
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2019/07_use_neural_network_recognize_handwriting/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
